2025
Deterministic Inference Across Tensor Parallel Sizes That Eliminates Training-Inference Mismatch
Ziyang ZHang*, Xinheng Ding*, Jiayi Yuan, Rixin Liu, Huizi Mao, Jiarong Xing, Zirui Liu (* equal contribution)
Under review. 2026
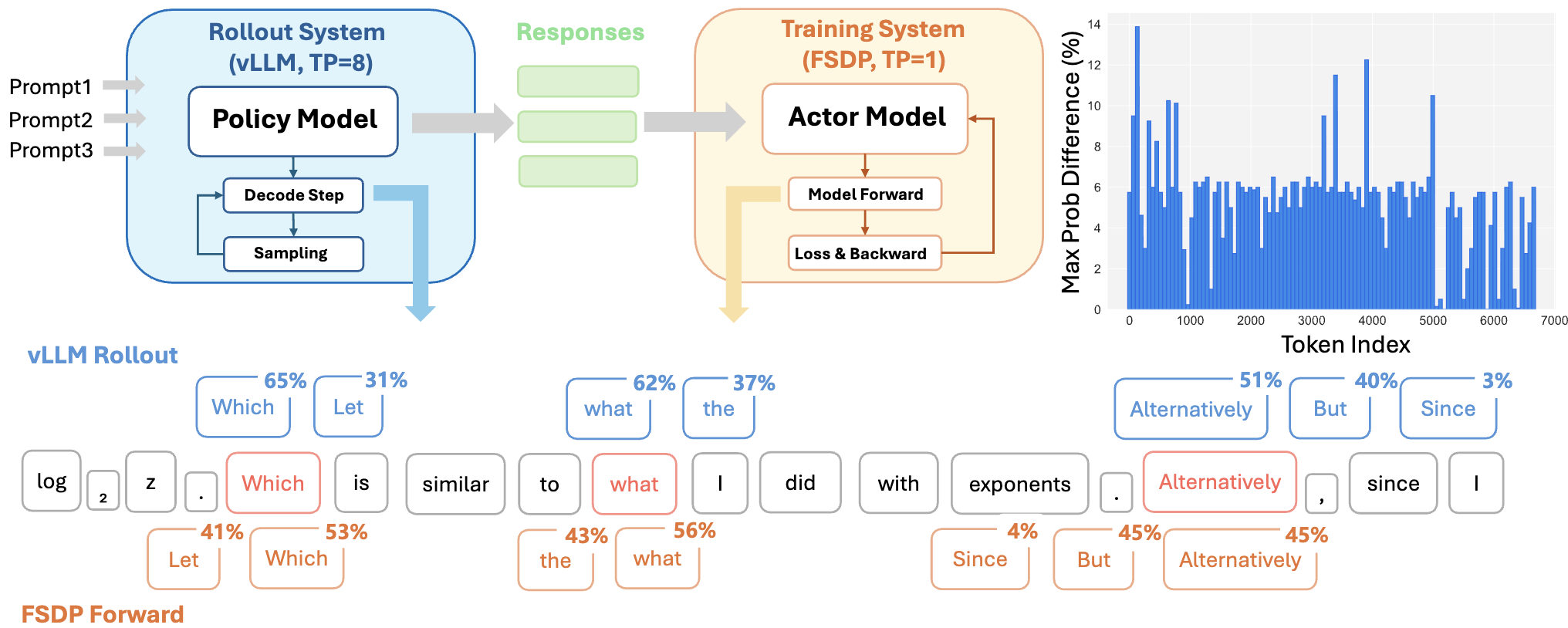
Deterministic inference is increasingly critical for large language model (LLM) applications such as LLM-asa-judge evaluation, multi-agent systems, and Reinforcement Learning (RL). However, existing LLM serving frameworks exhibit non-deterministic behavior: identical inputs can yield different outputs when system configurations (e.g., tensor parallel (TP) size, batch size) vary, even under greedy decoding. This arises from the non-associativity of floating-point arithmetic and inconsistent reduction orders across GPUs. While prior work has addressed batch-size–related nondeterminism through batch-invariant kernels, determinism across different TP sizes remains an open problem, particularly in RL settings, where the training engine typically uses Fully Sharded Data Parallel (i.e., TP = 1) while the rollout engine relies on multi-GPU TP to maximize the inference throughput, creating a natural mismatch between the two. This precision mismatch problem may lead to suboptimal performance or even collapse for RL training. We identify and analyze the root causes of TP-induced inconsistency and propose Tree-Based Invariant Kernels (TBIK), a set of TP-invariant matrix multiplication and reduction primitives that guarantee bit-wise identical results regardless of TP size. Our key insight is to align intra- and inter-GPU reduction orders through a unified hierarchical binary tree structure. We implement these kernels in Triton and integrate them into vLLM and FSDP. Experiments confirm zero probability divergence and bit-wise reproducibility for deterministic inference across different TP sizes. Also, we achieve bit-wise identical results between vLLM and FSDP in RL training pipelines with different parallel strategy.
Deterministic Inference Across Tensor Parallel Sizes That Eliminates Training-Inference Mismatch
Ziyang ZHang*, Xinheng Ding*, Jiayi Yuan, Rixin Liu, Huizi Mao, Jiarong Xing, Zirui Liu (* equal contribution)
Under review. 2026
Deterministic inference is increasingly critical for large language model (LLM) applications such as LLM-asa-judge evaluation, multi-agent systems, and Reinforcement Learning (RL). However, existing LLM serving frameworks exhibit non-deterministic behavior: identical inputs can yield different outputs when system configurations (e.g., tensor parallel (TP) size, batch size) vary, even under greedy decoding. This arises from the non-associativity of floating-point arithmetic and inconsistent reduction orders across GPUs. While prior work has addressed batch-size–related nondeterminism through batch-invariant kernels, determinism across different TP sizes remains an open problem, particularly in RL settings, where the training engine typically uses Fully Sharded Data Parallel (i.e., TP = 1) while the rollout engine relies on multi-GPU TP to maximize the inference throughput, creating a natural mismatch between the two. This precision mismatch problem may lead to suboptimal performance or even collapse for RL training. We identify and analyze the root causes of TP-induced inconsistency and propose Tree-Based Invariant Kernels (TBIK), a set of TP-invariant matrix multiplication and reduction primitives that guarantee bit-wise identical results regardless of TP size. Our key insight is to align intra- and inter-GPU reduction orders through a unified hierarchical binary tree structure. We implement these kernels in Triton and integrate them into vLLM and FSDP. Experiments confirm zero probability divergence and bit-wise reproducibility for deterministic inference across different TP sizes. Also, we achieve bit-wise identical results between vLLM and FSDP in RL training pipelines with different parallel strategy.

RouterArena: An Open Platform for Comprehensive Comparison of LLM Routers
Yifan Lu*, Rixin Liu*, Jiayi Yuan*, Xingqi Cui, Shenrun Zhang, Hongyi Liu, Jiarong Xing (* equal contribution)
The Fourteenth International Conference on Learning Representations (ICLR) 2026
Today's LLM ecosystem comprises a wide spectrum of models that differ in size, capability, and cost. No single model is optimal for all scenarios; hence, LLM routers have become essential for selecting the most appropriate model under varying circumstances. However, the rapid emergence of various routers makes choosing the right one increasingly challenging. To address this problem, we need a comprehensive router comparison and a standardized leaderboard, similar to those available for models. In this work, we introduce RouterArena, the first open platform enabling comprehensive comparison of LLM routers. RouterArena has (1) a principally constructed dataset with broad knowledge domain coverage, (2) distinguishable difficulty levels for each domain, (3) an extensive list of evaluation metrics, and (4) an automated framework for leaderboard updates. Leveraging our framework, we have produced the initial leaderboard with detailed metrics comparison as shown in Figure 1. We will make our platform open to the public soon.
RouterArena: An Open Platform for Comprehensive Comparison of LLM Routers
Yifan Lu*, Rixin Liu*, Jiayi Yuan*, Xingqi Cui, Shenrun Zhang, Hongyi Liu, Jiarong Xing (* equal contribution)
The Fourteenth International Conference on Learning Representations (ICLR) 2026
Today's LLM ecosystem comprises a wide spectrum of models that differ in size, capability, and cost. No single model is optimal for all scenarios; hence, LLM routers have become essential for selecting the most appropriate model under varying circumstances. However, the rapid emergence of various routers makes choosing the right one increasingly challenging. To address this problem, we need a comprehensive router comparison and a standardized leaderboard, similar to those available for models. In this work, we introduce RouterArena, the first open platform enabling comprehensive comparison of LLM routers. RouterArena has (1) a principally constructed dataset with broad knowledge domain coverage, (2) distinguishable difficulty levels for each domain, (3) an extensive list of evaluation metrics, and (4) an automated framework for leaderboard updates. Leveraging our framework, we have produced the initial leaderboard with detailed metrics comparison as shown in Figure 1. We will make our platform open to the public soon.
Who Routes the Router: Rethinking the Evaluation of LLM Routing Systems
Jiayi Yuan*, Yifan Lu*, Rixin Liu, Yu-Neng Chuang, Hongyi Liu, SHaochen Zhong, Yang Sui, Guanchu Wang, Jiarong Xing, Xia Hu (* equal contribution)
NeurIPS 2025 Workshop LLM Evaluation. 2025
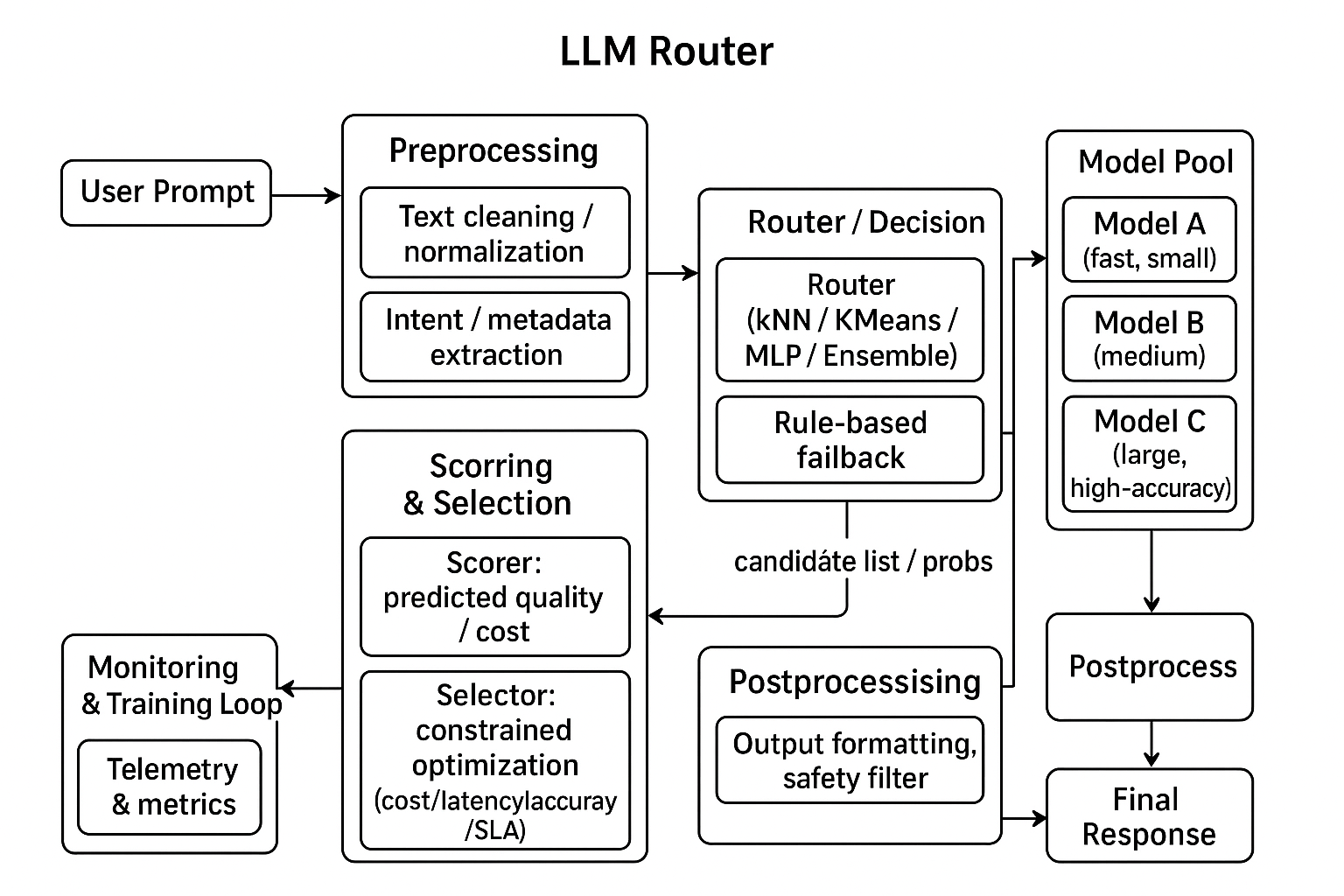
The proliferation of Large Language Models (LLMs), each with different capabilities and costs, has driven the need for LLM routers that intelligently and dynamically select the best model for a given query. Evaluating these routing systems is important yet inherently challenging due to the complex interplay of multiple factors: the selection of representative input queries, the composition of the model pool, and the definition of comprehensive evaluation metrics for optimal routing decisions. Through extensive analysis of existing benchmarks, we identify critical limitations that may lead to incomplete results and/or misleading conclusions about router performance: (1) limited task diversity, (2) imbalanced model pools, and (3) oversimplified evaluation methodologies. To address these limitations, we propose a novel evaluation framework that incorporates diverse task distributions, a balanced model pool with complementary model strengths, and multi-faceted metrics that reflect real-world deployment scenarios. We implement this framework as an open-source benchmark, the code and dataset are shared anonymously
Who Routes the Router: Rethinking the Evaluation of LLM Routing Systems
Jiayi Yuan*, Yifan Lu*, Rixin Liu, Yu-Neng Chuang, Hongyi Liu, SHaochen Zhong, Yang Sui, Guanchu Wang, Jiarong Xing, Xia Hu (* equal contribution)
NeurIPS 2025 Workshop LLM Evaluation. 2025
The proliferation of Large Language Models (LLMs), each with different capabilities and costs, has driven the need for LLM routers that intelligently and dynamically select the best model for a given query. Evaluating these routing systems is important yet inherently challenging due to the complex interplay of multiple factors: the selection of representative input queries, the composition of the model pool, and the definition of comprehensive evaluation metrics for optimal routing decisions. Through extensive analysis of existing benchmarks, we identify critical limitations that may lead to incomplete results and/or misleading conclusions about router performance: (1) limited task diversity, (2) imbalanced model pools, and (3) oversimplified evaluation methodologies. To address these limitations, we propose a novel evaluation framework that incorporates diverse task distributions, a balanced model pool with complementary model strengths, and multi-faceted metrics that reflect real-world deployment scenarios. We implement this framework as an open-source benchmark, the code and dataset are shared anonymously