
Hey, I'm Rixin, but you can call me Ryan. I'm a first-year CS PhD student at Rice University advised by Prof. Jiarong Xing. Prior to this, I got my B.E. in Computer Science and Technology from South China University of Technology in 2025.
About my research, overall, I’m a system researcher. My earlier work focused on high-performance networking, particularly on RDMA, programmable switches, and DPUs. Currently, my research centers on MLSys, aiming to address system and algorithmic challenges in a future dominated by specialized language models. My recent work primarily involves GPUs and LLM routing.
I’m always happy to connect and discuss possible collaborations. Please don’t hesitate to contact me if you’re interested in related topics.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
 Rice UniversityDepartment of Computer Science
Rice UniversityDepartment of Computer Science
Ph.D. StudentSep. 2025 - present -
 South China University of TechnologyB.E. in Computer Science and TechnologySep. 2021 - Jun. 2025
South China University of TechnologyB.E. in Computer Science and TechnologySep. 2021 - Jun. 2025
Honors & Awards
-
Recipient of the "Vibe Coding Excellence Award"2025
-
Awarded "Best Use of Ctrl-C Ctrl-V"2025
-
Recipient of the “Accidentally Fixed the Bug” Honor2025
News
Selected Publications (view all )

RouterArena: An Open Platform for Comprehensive Comparison of LLM Routers
Yifan Lu*, Rixin Liu*, Jiayi Yuan*, Xingqi Cui, Shenrun Zhang, Hongyi Liu, Jiarong Xing (* equal contribution)
Under review. 2025
Today's LLM ecosystem comprises a wide spectrum of models that differ in size, capability, and cost. No single model is optimal for all scenarios; hence, LLM routers have become essential for selecting the most appropriate model under varying circumstances. However, the rapid emergence of various routers makes choosing the right one increasingly challenging. To address this problem, we need a comprehensive router comparison and a standardized leaderboard, similar to those available for models. In this work, we introduce RouterArena, the first open platform enabling comprehensive comparison of LLM routers. RouterArena has (1) a principally constructed dataset with broad knowledge domain coverage, (2) distinguishable difficulty levels for each domain, (3) an extensive list of evaluation metrics, and (4) an automated framework for leaderboard updates. Leveraging our framework, we have produced the initial leaderboard with detailed metrics comparison as shown in Figure 1. We will make our platform open to the public soon.
RouterArena: An Open Platform for Comprehensive Comparison of LLM Routers
Yifan Lu*, Rixin Liu*, Jiayi Yuan*, Xingqi Cui, Shenrun Zhang, Hongyi Liu, Jiarong Xing (* equal contribution)
Under review. 2025
Today's LLM ecosystem comprises a wide spectrum of models that differ in size, capability, and cost. No single model is optimal for all scenarios; hence, LLM routers have become essential for selecting the most appropriate model under varying circumstances. However, the rapid emergence of various routers makes choosing the right one increasingly challenging. To address this problem, we need a comprehensive router comparison and a standardized leaderboard, similar to those available for models. In this work, we introduce RouterArena, the first open platform enabling comprehensive comparison of LLM routers. RouterArena has (1) a principally constructed dataset with broad knowledge domain coverage, (2) distinguishable difficulty levels for each domain, (3) an extensive list of evaluation metrics, and (4) an automated framework for leaderboard updates. Leveraging our framework, we have produced the initial leaderboard with detailed metrics comparison as shown in Figure 1. We will make our platform open to the public soon.
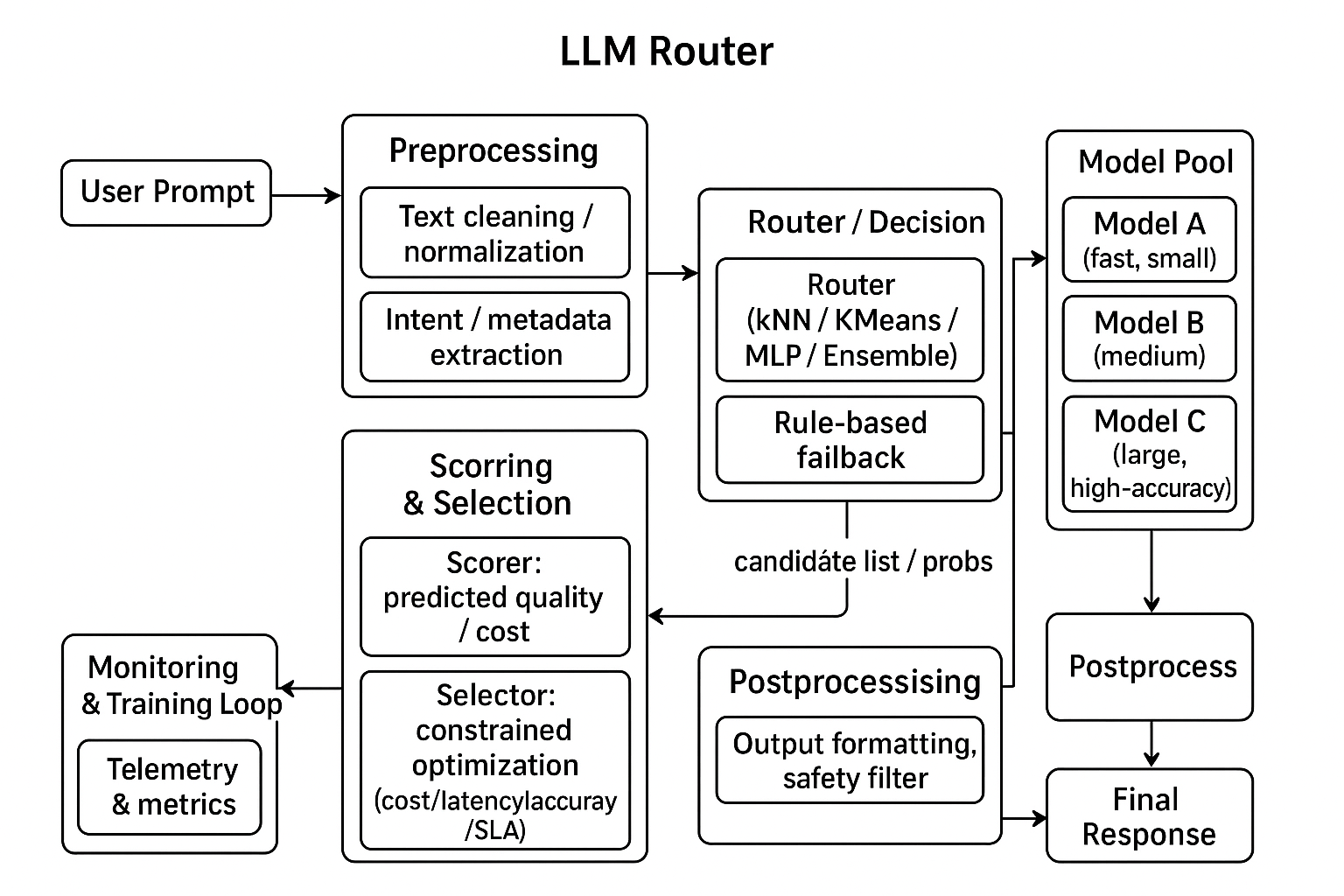
Who Routes the Router: Rethinking the Evaluation of LLM Routing Systems
Jiayi Yuan*, Yifan Lu*, Rixin Liu*, Yu-Neng Chuang, Hongyi Liu, SHaochen Zhong, Yang Sui, Guanchu Wang, Jiarong Xing, Xia Hu (* equal contribution)
NeurIPS 2025 Workshop LLM Evaluation. 2025
The proliferation of Large Language Models (LLMs), each with different capabilities and costs, has driven the need for LLM routers that intelligently and dynamically select the best model for a given query. Evaluating these routing systems is important yet inherently challenging due to the complex interplay of multiple factors: the selection of representative input queries, the composition of the model pool, and the definition of comprehensive evaluation metrics for optimal routing decisions. Through extensive analysis of existing benchmarks, we identify critical limitations that may lead to incomplete results and/or misleading conclusions about router performance: (1) limited task diversity, (2) imbalanced model pools, and (3) oversimplified evaluation methodologies. To address these limitations, we propose a novel evaluation framework that incorporates diverse task distributions, a balanced model pool with complementary model strengths, and multi-faceted metrics that reflect real-world deployment scenarios. We implement this framework as an open-source benchmark, the code and dataset are shared anonymously
Who Routes the Router: Rethinking the Evaluation of LLM Routing Systems
Jiayi Yuan*, Yifan Lu*, Rixin Liu*, Yu-Neng Chuang, Hongyi Liu, SHaochen Zhong, Yang Sui, Guanchu Wang, Jiarong Xing, Xia Hu (* equal contribution)
NeurIPS 2025 Workshop LLM Evaluation. 2025
The proliferation of Large Language Models (LLMs), each with different capabilities and costs, has driven the need for LLM routers that intelligently and dynamically select the best model for a given query. Evaluating these routing systems is important yet inherently challenging due to the complex interplay of multiple factors: the selection of representative input queries, the composition of the model pool, and the definition of comprehensive evaluation metrics for optimal routing decisions. Through extensive analysis of existing benchmarks, we identify critical limitations that may lead to incomplete results and/or misleading conclusions about router performance: (1) limited task diversity, (2) imbalanced model pools, and (3) oversimplified evaluation methodologies. To address these limitations, we propose a novel evaluation framework that incorporates diverse task distributions, a balanced model pool with complementary model strengths, and multi-faceted metrics that reflect real-world deployment scenarios. We implement this framework as an open-source benchmark, the code and dataset are shared anonymously